Cómo Utilizar¶
Cómo Acceder¶
El acceso a nuestro clúster puede realizarse a través de Open OnDemand o mediante el Terminal de JupyterLab (K8S). En ambas opciones, es imprescindible poseer una cuenta válida en el entorno computacional de LIneA. Si no tiene una cuenta, contacte al Service Desk por correo (helpdesk@linea.org.br) para más información.
Atención
Aún teniendo una cuenta activa en LIneA, el acceso al entorno de procesamiento HPC no es automático. Para más información contacte al Service Desk en helpdesk@linea.org.br.
Accediendo por terminal de JupyterLab
En la pantalla inicial de su Jupyter Notebook, en la sección "Other", encontrará el botón del terminal. Al hacer clic en él, será redirigido a un terminal Linux, inicialmente ubicado en su directorio home. Para acceder al Cluster Apollo, simplemente ejecute el siguiente comando:
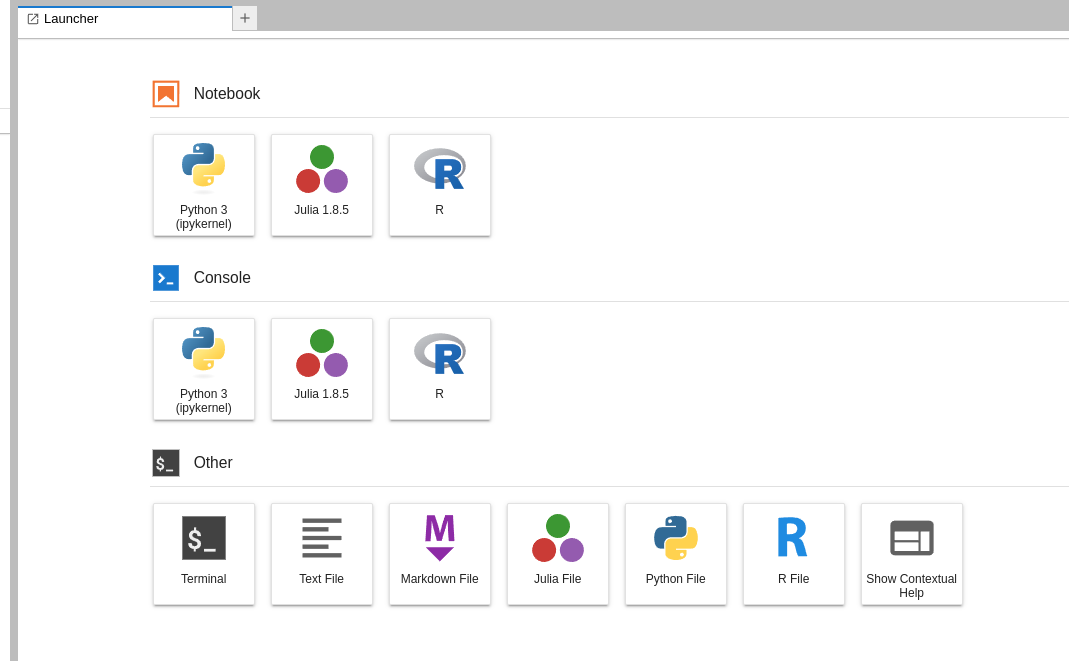{kind=link}
ssh loginapl01
$HOME y $SCRATCH
Los nodos de computación no tienen acceso a su directorio home de usuario. Mueva o copie todos los archivos necesarios para el envío de su job a su directorio SCRATCH.
Cómo usar el área SCRATCH¶
Su directorio de SCRATCH es el lugar donde puede dirigir los archivos de resultados de su trabajo, así como almacenar datos temporalmente que el código utiliza en el momento del procesamiento.
- Para acceder a su directorio SCRATCH:
cd $SCRATCH
- Para enviar archivos a su directorio SCRATCH:
cp <ARCHIVO> $SCRATCH
Limpieza automática del Scratch¶
Scratch es un área de almacenamiento temporal para los archivos de salida y procesamiento de trabajos realizados en el clúster. Para mantener el medio ambiente organizado y garantizar el espacio disponible para todos, está vigente un script de limpieza automático, que funciona una vez por semana.
Este proceso elimina los archivos a los que no se ha accedido dentro del período establecido de retención, actualmente 45 días.
Los archivos de configuración esenciales (por ejemplo, .bashrc, .bash_profile, .ssh, etc.) se conservan automáticamente y no entran en el proceso de exclusión.
Atención
El scratch no debe usarse para el almacenamiento permanente. Recomendamos mover datos importantes a su directorio home.
Cómo usar el área de script¶
Su directorio de SCRIPTS es el lugar donde puede almacenar scripts, códigos para ejecutarse en el clúster. También se recomienda utilizar esta área para crear un entorno de conda.
Para acceder a su directorio de SCRIPTS:
cd $SCRIPTS
Ser Consciente
El área de script no está incluida en la rutina de backups. Por lo tanto, no debe usarse como almacenamiento de datos permanente.
Cómo Enviar un Job¶
Un Job solicita recursos de computación y especifica las aplicaciones a iniciar en esos recursos, junto con cualquier dato/opción de entrada y directiva de salida. La gestión y programación de tareas y recursos del clúster se realiza a través de Slurm. Por lo tanto, para enviar un Job necesita usar un script como el siguiente:
#!/bin/bash
#SBATCH -p PARTICIÓN #Nombre de la Partición a usar
#SBATCH --nodelist=NODO #Nombre del Nodo a asignar
#SBATCH -J simple-job #Nombre del Job
#----------------------------------------------------------------------------#
##ruta al código ejecutable
EXEC=/scripts/USUARIO/CODIGO.EJECUTABLE
srun $EXEC
En este script debe especificar: el nombre de la cola (Partition) a usar; el nombre del nodo a asignar para la ejecución del Job; y la ruta al código/programa a ejecutar.
ADVERTENCIA
Está estrictamente prohibido enviar jobs directamente a la máquina loginapl01. Cualquier código ejecutándose en esta máquina será interrumpido inmediatamente sin previo aviso.
- Para enviar el Job:
cd $SCRATCH
sbatch $SCRIPTS/PATH/TO/script-submit-job.sh
Si el script es correcto habrá una salida que indica el ID del job.
- Para verificar el progreso e información del Job:
scontrol show job <ID>
- Para cancelar el Job:
scancel <ID>
Acceso a internet
Los nodos de computación no tienen acceso a internet. Paquetes y bibliotecas deben instalarse desde loginapl01 en su área de scripts.
EUPS (gestor de paquetes)¶
EUPS es un gestor de paquetes alternativo (y oficial de LSST) que permite cargar variables de entorno e incluir la ruta a programas y bibliotecas de forma modular.
- Para cargar EUPS:
Info
Actualmente, EUPS se carga automáticamente después de que el usuario accede a cualquier máquina del clúster Apollo.
- Para listar todos los paquetes disponibles:
eups list
- Para listar un paquete específico:
eups list | grep <PAQUETE>
- Para cargar un paquete en la sesión actual:
setup <NOMBRE DEL PAQUETE> <VERSIÓN DEL PAQUETE>
- Para eliminar el paquete cargado:
unsetup <NOMBRE DEL PAQUETE> <VERSIÓN DEL PAQUETE>
Conda en el entorno HPC¶
Visión general¶
Conda está disponible de forma centralizada en todos los nodos del clúster en /opt/conda.
Los entornos conda del sistema son mantenidos por el equipo de operaciones y son de solo lectura.
(a partir de aquí los llamaremos env o envs)
Cada usuario puede crear y gestionar sus propios envs personales.
Verificando Conda¶
Conda ya está disponible en cuanto inicia sesión. Para verificar:
conda --version
Envs disponibles¶
Para listar todos los envs disponibles, del sistema y personales:
conda env list
Ejemplo de salida:
# conda environments:
base /opt/conda
base-science /opt/conda/envs/base-science
mi-env /home/usuario/.conda/envs/mi-env
analisis-xray /scripts/usuario/.conda/envs/analisis-xray
proyecto-survey /scripts/cl/prj/proyecto-survey
Los envs en /opt/conda/envs/ son mantenidos por soporte y no pueden modificarse.
Activando un env¶
conda activate base-science
Para volver al env base:
conda deactivate
Creando envs personales¶
En home (recomendado para Jupyter y desarrollo)¶
conda create -n mi-env python=3.11
El env se creará en ~/.conda/envs/mi-env, accesible tanto desde el clúster como desde Jupyter.
En /scripts (recomendado para jobs en el clúster)¶
conda create -p /scripts/$USER/.conda/envs/mi-env python=3.11
Para un proyecto compartido¶
Si aún no existe, solicite al helpdesk@linea.org.br la creación del directorio del proyecto en /scripts/cl/prj/<proyecto>.
Después de la creación:
conda create -p /scripts/cl/prj/<proyecto> python=3.11
ATENCION
/scripts no tiene garantía de backup. Mantenga sus archivos de definición de env (environment.yml) versionados en git.
Eliminando un env¶
conda env remove -n mi-env
O por ruta completa:
conda env remove -p /scripts/$USER/.conda/envs/mi-env
Instalando paquetes¶
Active siempre el env antes de instalar:
conda activate mi-env
conda install numpy scipy matplotlib
Para instalar desde un canal específico:
conda install -c conda-forge astropy
Para instalar con pip dentro del env:
pip install mi-paquete
ATENCION
Prefiera conda install antes de usar pip para evitar conflictos de dependencias.
Eliminando paquetes¶
conda activate mi-env
conda remove numpy
Exportando y reproduciendo envs¶
Para exportar la definición del env:
conda activate mi-env
conda env export > environment.yml
Para recrear el env a partir del archivo:
conda env create -f environment.yml
Info
Recomendamos versionar environment.yml en git para garantizar la reproducibilidad de sus experimentos.
Usando un env en Jobs¶
En jobs enviados al scheduler, active conda explícitamente en el script:
#!/bin/bash
#SBATCH --job-name=mi-job
#SBATCH --ntasks=1
source /opt/conda/etc/profile.d/conda.sh
conda activate mi-env
python mi_script.py
Info
El env activo en su shell no se hereda automáticamente por el job. source y conda activate son obligatorios en el script.
Buenas prácticas¶
- No instale conda en
/scratch- scratch es para datos temporales de I/O, no para entornos. Los entornos allí se perderán. - No instale conda directamente en
/scripts/<username>- use siempre el subdirectorio.conda/envsdentro de su directorio en/scripts. - Mantenga
environment.ymlen git - es la única garantía de reproducibilidad de suenv. - Use
mambaen lugar decondapara instalar paquetes - la resolución de dependencias es más rápida:mamba install numpy scipy - Los entornos grandes pueden impactar el rendimiento del filesystem. Si su job usa muchos paquetes de forma intensiva, considere hablar con helpdesk sobre
conda-pack.
Dónde se crean los envs¶
| Contexto | Ruta estándar | Persistente |
|---|---|---|
conda create -n nombre |
~/.conda/envs/ |
✅ sí |
| Jupyter (k8s) | ~/.conda/envs/ |
✅ sí |
| Job en el clúster | /scripts/$USER/.conda/envs/ |
⚠️ sin backup |
| Proyecto compartido | /scripts/cl/prj/<proyecto> |
⚠️ sin backup |
Usando conda-pack en Jobs de gran escala¶
conda-pack empaqueta un env conda completo en un archivo .tar.gz que puede descomprimirse y usarse directamente en el nodo de cómputo, sin acceso al NFS durante la ejecución.
Esto se recomienda para jobs que corren en muchos nodos al mismo tiempo, evitando una ráfaga de accesos a /opt/conda vía NFS en el momento de activación.
Los envs del sistema ya están disponibles empaquetados en /opt/conda/packed/:
/opt/conda/packed/
└── base-science.tar.gz
Uso en el script del job¶
#!/bin/bash
#SBATCH --job-name=mi-job
# Descomprime el env en el scratch local del nodo
mkdir -p /scratch/$USER/envs/base-science
tar -xzf /opt/conda/packed/base-science.tar.gz -C /scratch/$USER/envs/base-science
# Activa localmente, sin depender de NFS
source /scratch/$USER/envs/base-science/bin/activate
# Ejecuta normalmente
python mi_script.py
# Limpia el env al final del job
rm -rf /scratch/$USER/envs/base-science
Empaquetando un env personal¶
Si desea usar conda-pack con un env personal:
conda activate mi-env
conda pack -o /scratch/$USER/mi-env.tar.gz
Info
El archivo .tar.gz puede ser grande según el entorno.
Cuándo usar¶
| Situación | Recomendado |
|---|---|
| Desarrollo interactivo en login | ❌ |
| Jupyter (k8s) | ❌ |
| Jobs cortos en pocos nodos | ⚠️ opcional |
| Jobs largos o con muchos nodos simultáneos | ✅ |
| Entornos con muchos paquetes | ✅ |
Soporte¶
En caso de dudas o para solicitar la creación de envs del sistema, abra un ticket con helpdesk.
Comandos útiles de Slurm¶
Para aprender sobre todas las opciones disponibles para cada comando, ingrese man <comando> mientras esté conectado al entorno del Cluster.
| Comando | Definición |
|---|---|
| sbatch | Envía scripts de trabajos a la cola de ejecución |
| squeue | Muestra estado de los jobs |
| scontrol | Usado para mostrar estado de Slurm (varias opciones disponibles solo para root) |
| sinfo | Muestra estado de particiones y nodos |
| salloc | Envía un job para ejecución o inicia un trabajo en tiempo real |