LSST Photo-z Server
Advertencia¶
Advertencia sobre la versión ES
Esta es una traducción del documento original disponible en inglés. Se ha optado por no traducir los nombres de los pipelines y tipos de productos para mantener los nombres consistentes con los que aparecen en Photo-z Server. Asimismo, no se han traducido los fragmentos de código para mantenerlos consistentes con el tutorial disponible como Jupyter notebook en el repositorio de la biblioteca Python pzserver.
Introducción¶
Inspirado en DES Science Portal (Gschwend et al., 2018; Fausti Neto et al., 2018), Photo-z Server es un servicio en línea complementario a Rubin Science Platform (RSP) para alojar y producir productos de datos ligeros relacionados con photo-z y ofrecer herramientas de gestión de datos que permiten compartir productos de datos entre usuarios de RSP, adjuntar y compartir metadatos relevantes y facilitar el rastreo de procedencia.
El servicio se aloja en Brazilian Independent Data Access Center (IDAC) y está abierto a toda la comunidad LSST, sin restricciones geográficas. Su diseño es lo más amplio y genérico posible para facilitar la colaboración de todas las colaboraciones científicas de LSST que trabajan con productos de datos de photo-z. Según lo exige el programa de contribuciones in-kind de LSST, el código fuente está disponible públicamente en GitHub.
El Photo-z Server se diseñó para ayudar a los usuarios de RSP a participar en la Photo-z (PZ) Validation Cooperative. Esta iniciativa del equipo Data Management (DM) se llevará a cabo durante la fase de commissioning de LSST (consulte la nota técnica dmtn-049 para obtener más información). El grupo de coordinación de PZ recibirá credenciales de usuario administrador con permisos especiales para agregar productos de datos etiquetados como official data products. Estos incluirán conjuntos estandarizados de entrenamiento y validación utilizados para comparar el rendimiento de los algoritmos, así como un medio para recopilar resultados de múltiples usuarios.
Más allá de la PZ Validation Cooperative, el Photo-z Server seguirá siendo un recurso para la comunidad LSST en los próximos años. Los usuarios de RSP podrán seguir utilizándolo para organizar, rastrear y compartir archivos ligeros con diversos resultados de pruebas.
Datasets
Los administradores de Photo-z Server mantienen y actualizan periódicamente una lista seleccionada de recursos de datos para apoyar a la comunidad LSST con productos de datos relacionados con photo-z. Las descripciones detalladas y los enlaces a cada producto de datos están disponibles en una página separada.
Sitio web de Photo-z Server¶
La interfaz de usuario principal del Photo-z Server es su sitio web en pzserver.linea.org.br.
Las tres tarjetas de la página de inicio conducen a la lista de productos de datos (izquierda y centro) o a los pipelines del Photo-z Server (derecha).
En la página de la lista de productos de datos, los usuarios pueden explorar, buscar y filtrar los productos cargados por otros usuarios o creados con un pipeline del Photo-z Server. Los productos de datos cargados en Photo-z Server se vuelven automáticamente visibles, descargables y compartibles para todos los usuarios registrados.
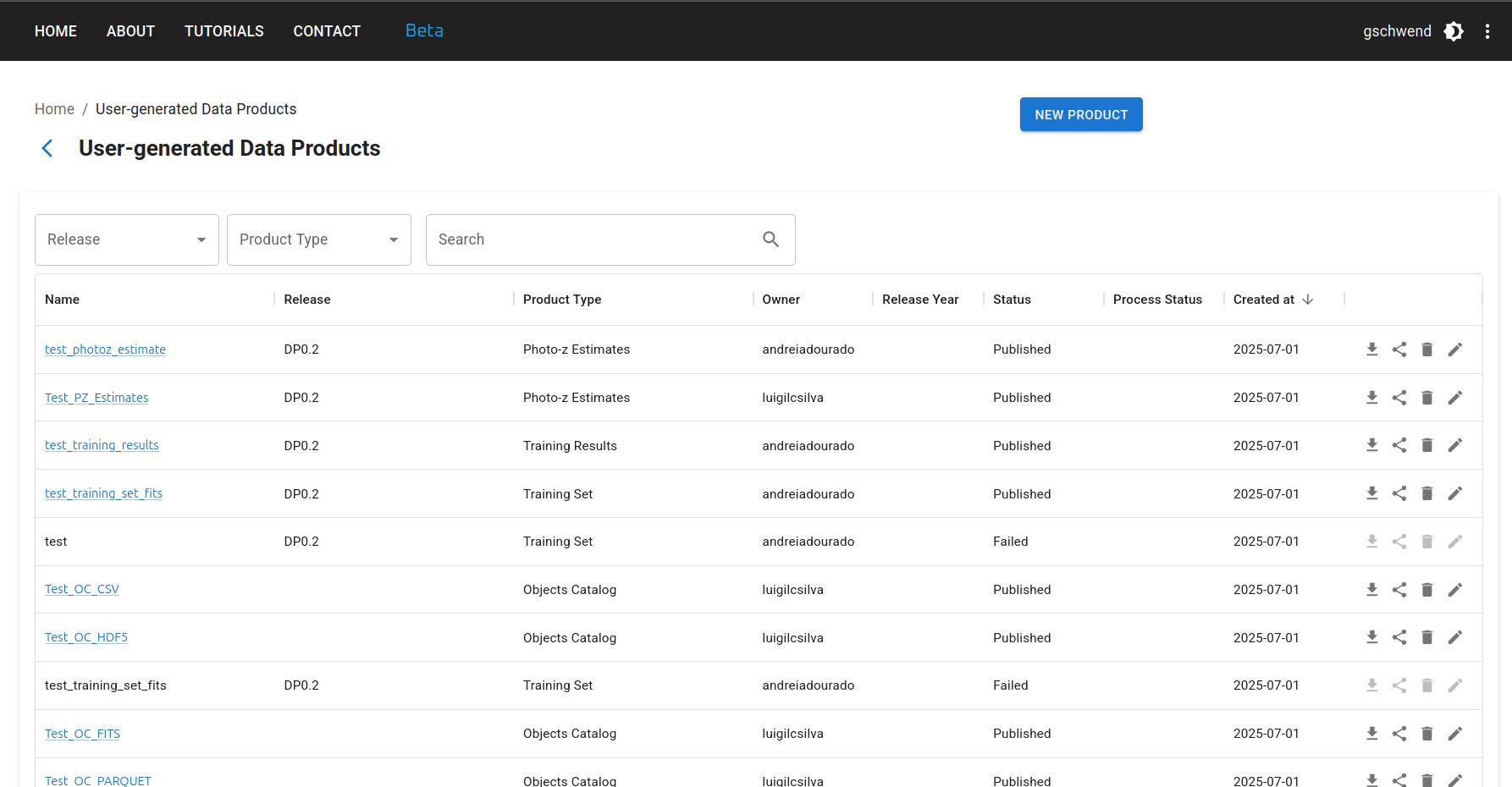
Cargar un nuevo producto de datos¶
Para cargar un nuevo producto de datos, haga clic en el botón NUEVO PRODUCTO en la esquina superior derecha de la página de productos de datos generados por el usuario y complete el formulario con los metadatos relevantes en cuatro pasos:
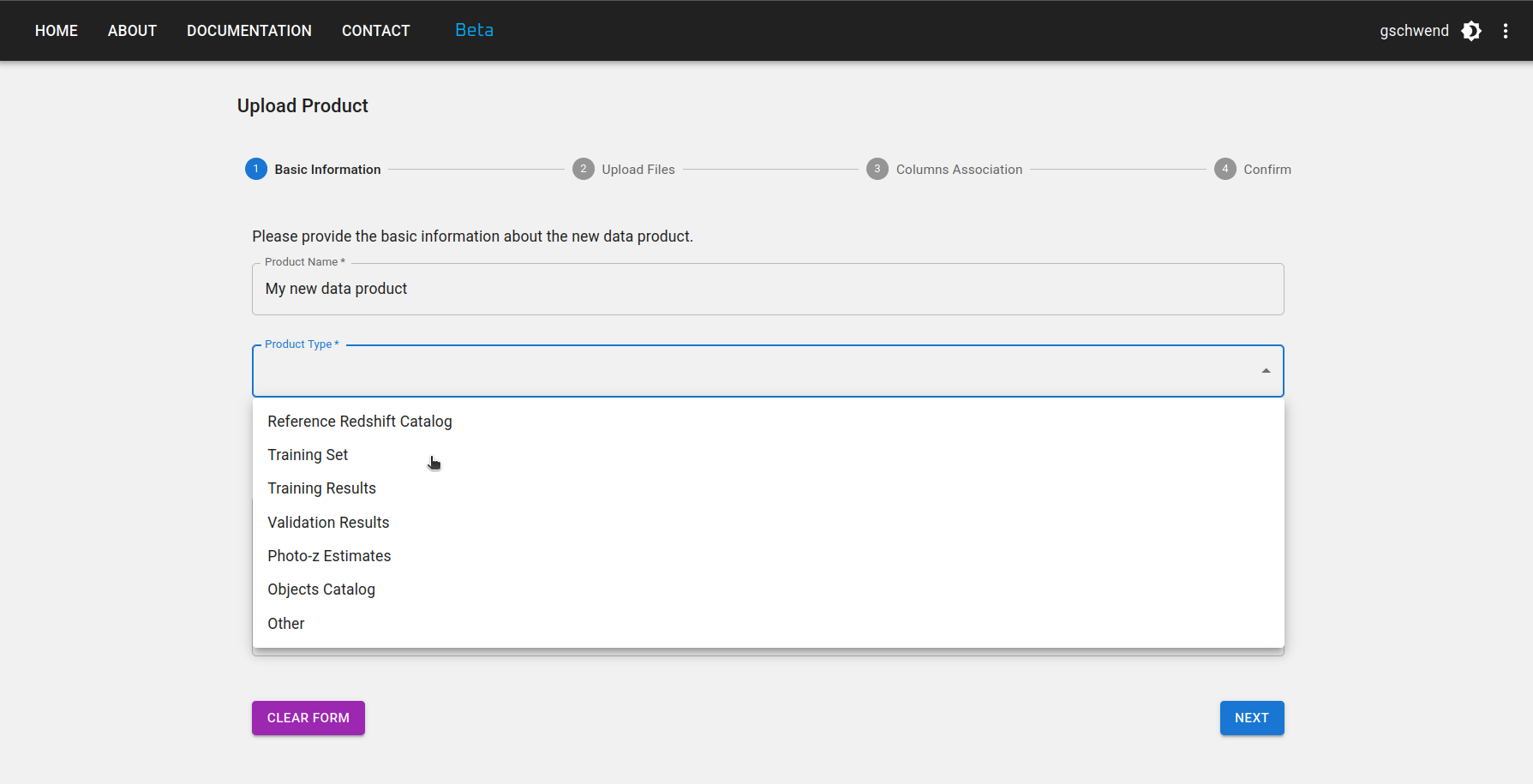
Paso 1: Introduzca un nombre corto y mnemotécnico para su nuevo producto de datos. Seleccione el tipo de producto de datos que va a cargar (p. ej., Reference Redshift Catalog, Training Set, etc.) y el release al que pertenece (si corresponde).
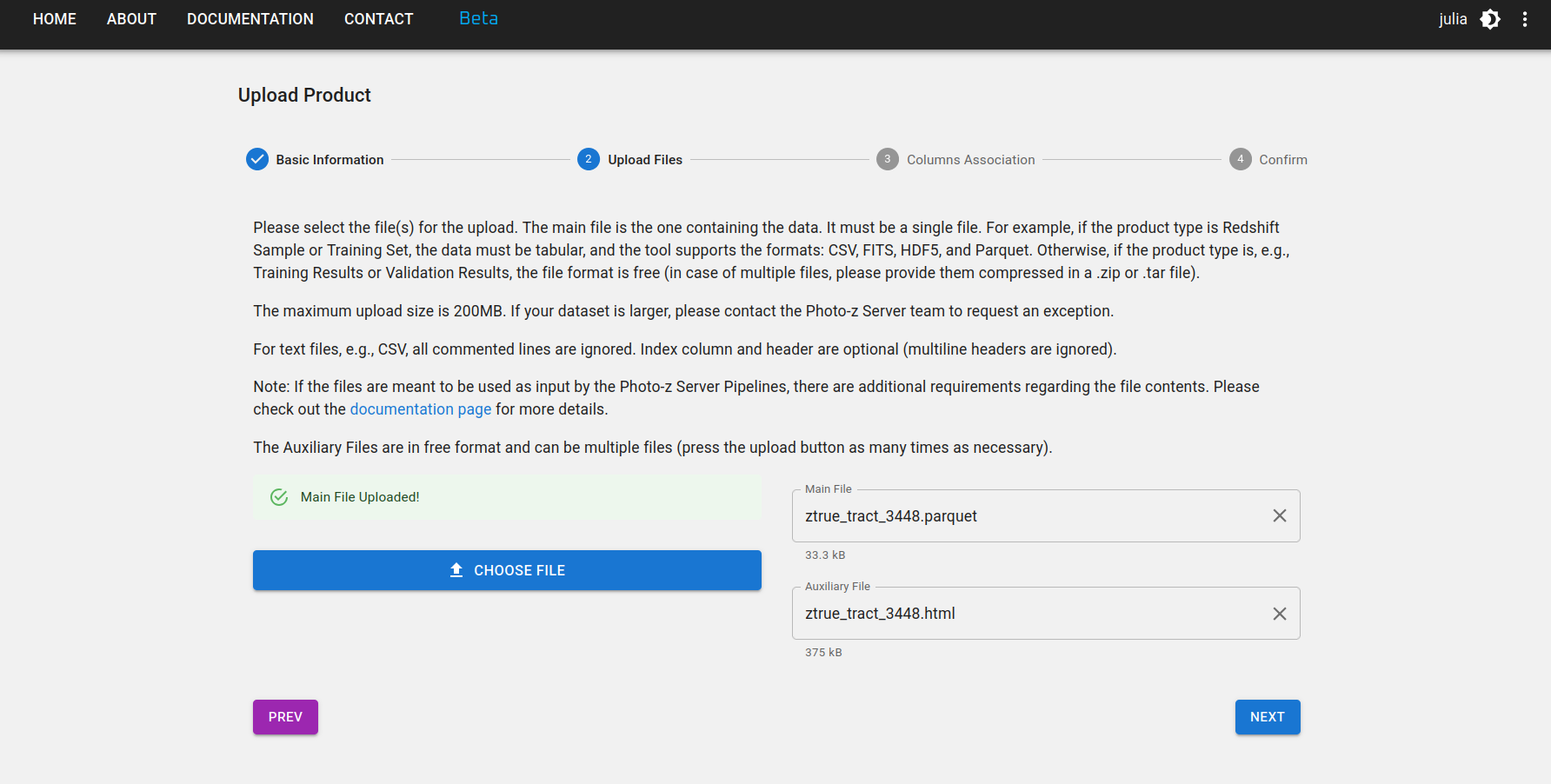
Paso 2: Seleccione su archivo principal y todos los archivos auxiliares que desee cargar. El archivo principal contiene el producto de datos, mientras que los archivos auxiliares pueden incluir documentación, descripción o cualquier otra información relevante sobre el producto.
Si el producto de datos es tabular, la herramienta de carga podría requerir formatos de archivo específicos según su tipo. Los formatos actualmente admitidos son: CSV, FITS, HDF5 y Parquet. Póngase en contacto con el equipo de desarrollo si su caso científico requiere un formato de archivo diferente o si su archivo supera el límite de 200 MB.
Paso 3: Si el producto de datos es un Reference Redshift Catalog o un Training Set, algunas columnas son obligatorias. Los nombres de las columnas son libres, pero debe proporcionar la asociación con su significado y UCDs en el estándar IVOA, como se muestra en la figura siguiente.
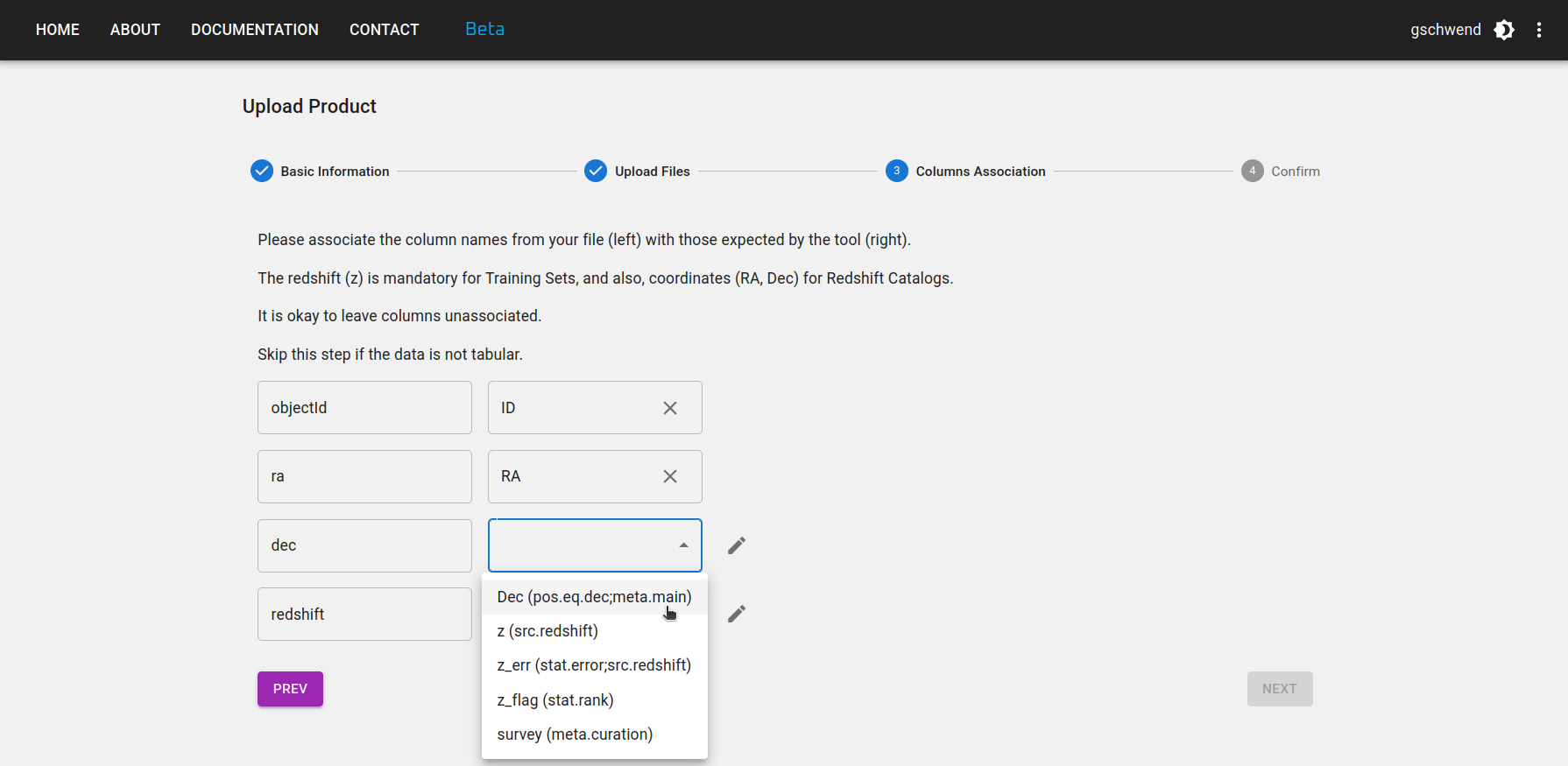
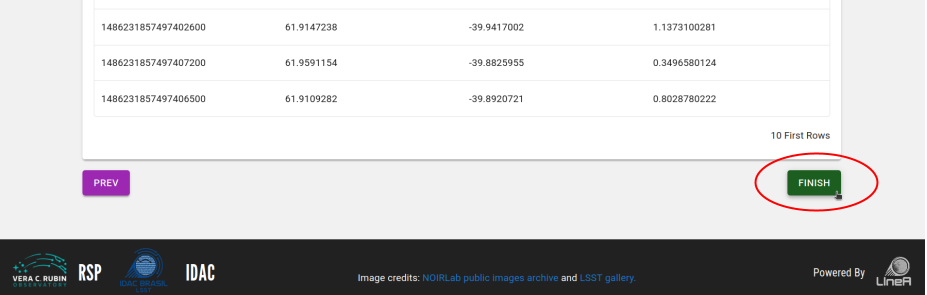
Paso 4: Revise su información y vuelva a los pasos anteriores si es necesario. No olvide hacer clic en el botón FINISH en la parte inferior de la página para enviar su producto de datos.
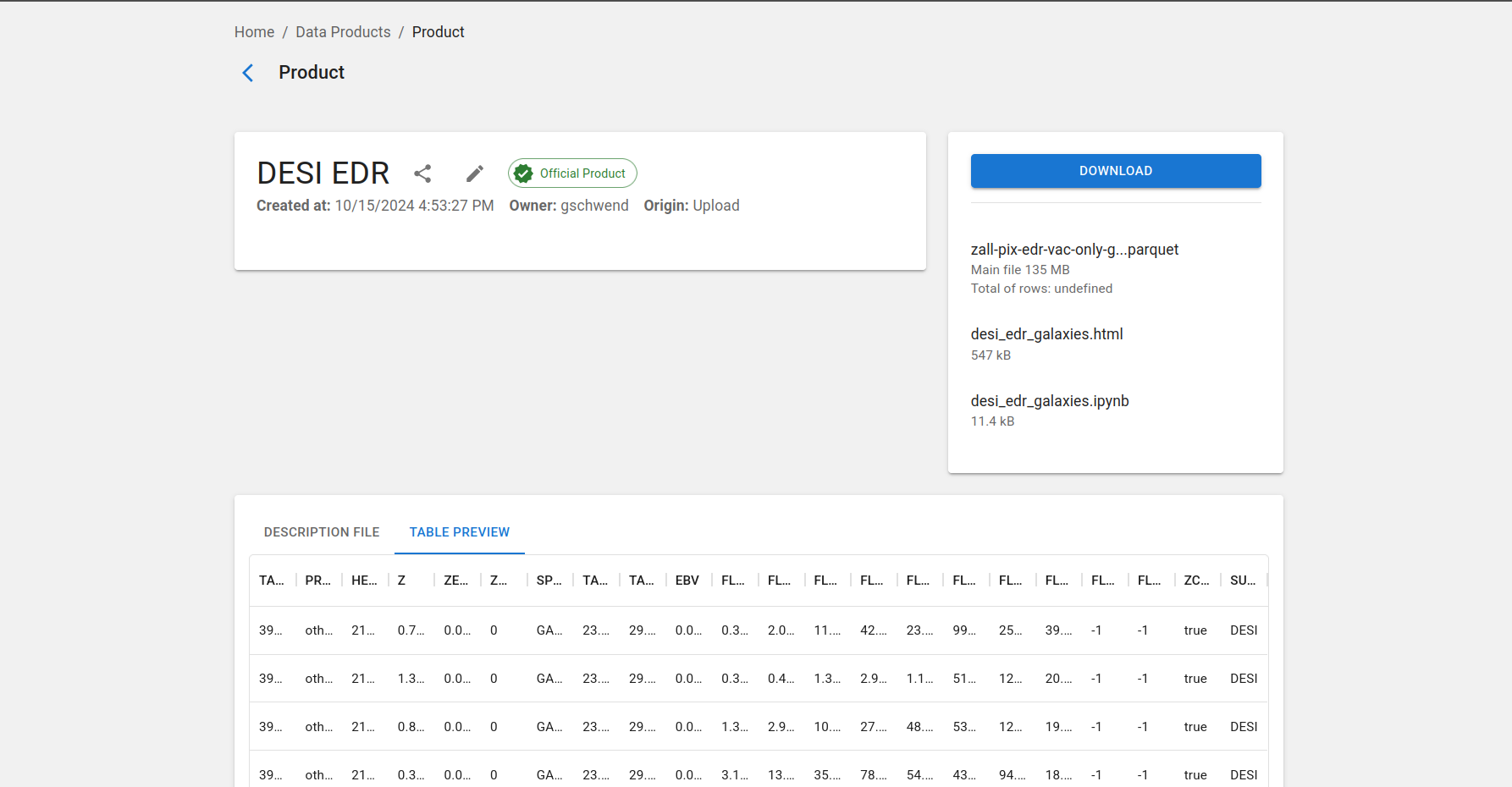
Descargar un producto de datos¶
Para descargar un producto de datos, haga clic en el icono ![]() en la fila del producto en la página de productos de datos generados por el usuario. Al hacer clic, se generará un archivo comprimido .zip con todo el contenido del producto, incluyendo los archivos de descripción auxiliares.
en la fila del producto en la página de productos de datos generados por el usuario. Al hacer clic, se generará un archivo comprimido .zip con todo el contenido del producto, incluyendo los archivos de descripción auxiliares.
También hay un botón en la página de detalles del producto, a la que se puede acceder haciendo clic en el nombre del producto en la lista.
Compartir productos de datos¶
Para compartir un producto de datos, haga clic en el icono ![]() en la fila del producto en la página de productos de datos generados por el usuario o en la página de detalles del producto. Al hacer clic, se abrirá una ventana emergente con el internal_name y la URL del producto. Puede copiar la información para compartirla con otros usuarios.
en la fila del producto en la página de productos de datos generados por el usuario o en la página de detalles del producto. Al hacer clic, se abrirá una ventana emergente con el internal_name y la URL del producto. Puede copiar la información para compartirla con otros usuarios.
internal_name
Cada producto de datos posee un nombre único («internal_name»), compuesto automáticamente por el sistema como un número id único seguido del nombre elegido por el usuario, con los espacios en blanco sustituidos por guiones bajos. Este nombre es la URL de la página de detalles del producto de datos en el sitio web del Photo-z Server:
https://pzserver.linea.org.br/product/internal_name
y es la clave para acceder a los datos mediante la API Python del Photo-z Server (véanse los detalles a continuación). La forma más sencilla de compartir un producto de datos es proporcionar el internal_name o la URL del producto, que conduce a la página de descarga del producto.
Tipos de productos¶
Reference Redshift Catalog¶
En el contexto del Photo-z Server, los Reference Redshift Catalogs se definen como cualquier catálogo que contenga coordenadas ecuatoriales esféricas y mediciones de redshift (generalmente espectroscópicas o redshift verdaderos para simulaciones).
Columnas obligatorias:
- Ascensión recta [grados] -
float - Declinación [grados] -
float - Redshift -
float
Columna recomendada:
- Error de redshift -
float
Un Reference Redshift Catalog puede incluir datos de un único relevamiento espectroscópico o una combinación de datos de varias fuentes.
Requisitos del pipeline
Si se pretende utilizar el Reference Redshift Catalog como datos de entrada para el pipeline Combine Redshift Catalogs, aplicando la función de resolución de duplicados (consulte detalles del pipeline aquí), se recomienda incluir las siguientes columnas:
- Indicador de calidad (asociar con z_flag en el paso 3 de la carga) -
integer,floatostring(el indicador de calidad original del catálogo fuente, si está disponible). - Tipo de medición -
string(p. ej., «s» para «spectroscopic», «g» para «grism/prism», «p» para «photometric», según lo adoptado en SITCOMTN-154) - Nombre del relevamiento (asociar con survey en el paso 3 de la carga) -
string(p. ej., «DESI», «COSMOS2025», «JADES», etc.) - Otras columnas con información adicional que desee utilizar para la resolución de duplicados (p. ej., resolución del instrumento).
Training Set¶
En el contexto del Photo-z Server, los Training Sets se definen como el producto del cruce espacial entre un Reference Redshift Catalog (relevamiento individual o compilación) y los datos fotométricos, en este caso, el LSST Object Catalog. El pipeline Training Set Maker del Photo-z Server permite a los usuarios crear Training Sets personalizados basados en los Reference Redshift Catalogs disponibles (consulte detalles del pipeline aquí).
Subconjuntos de train/test
Los training sets se suelen dividir en dos o más subconjuntos para la validación de photo-z. Si el propietario del training set ha definido previamente qué objetos deben pertenecer a cada subconjunto (entrenamiento y validación/prueba), esta información debe estar disponible como una columna adicional en la tabla o como instrucciones claras para reproducir la separación de los subconjuntos en la descripción del producto de datos. En el caso de dos archivos separados, cada uno debe cargarse por separado y se convertirá en un producto de datos independiente, ambos con el tipo de producto «Training Set». Su destino puede indicarse explícitamente en el nombre y/o descripción del producto.
Training sets basados en imágenes
El tipo Training Set solo admite datos a nivel de catálogo. Los training sets basados en imágenes, utilizados comúnmente por algoritmos de deep learning, no son compatibles. En este caso, utilice el tipo de producto «Other» y proporcione una descripción clara del formato de los datos en la descripción del producto.
Para garantizar la flexibilidad en los observables, la única columna obligatoria es el redshift (float). Otras columnas esperadas son:
objectIdde LSST Objects Catalog -integer- Observables (magnitudes y/o colores, o flujos) de LSST Objects Catalog -
float - Errores de los observables -
float - Ascensión recta [grados] -
float - Declinación [grados] -
float - Indicador de calidad -
integer,floatostring - Indicador de subconjunto -
integer,floatostring
Training Results¶
Los resultados de entrenamiento de los algoritmos basados en machine learning también pueden alojarse en Photo-z Server para su uso compartido y reutilización. Este tipo de producto permite archivos en formato libre. Cuando los resultados de entrenamiento se generan con el método inform de RAIL, se almacenan como archivos pickle.
Validation Results¶
El tipo de producto Validation Results está diseñado para identificar los resultados de cualquier procedimiento de validación de photo-z. Puede utilizarse para almacenar los resultados de PZ Validation Cooperative o cualquier otra tarea de validación.
Este tipo de producto es bastante genérico. Puede contener estimaciones de photo-z (estimaciones individuales y/o PDF) de un conjunto de prueba, métricas de validación, gráficos QQ-PIT, etc. Los usuarios pueden cargar un archivo principal y una lista de archivos auxiliares en cualquier formato.
Photo-z Estimates¶
Las Photo-z Estimates son el resultado de cualquier procedimiento de estimación de photo-z, generalmente la salida del método estimate de RAIL. Si los datos superan el límite de carga de archivos (200 MB), la entrada del producto solo almacenará los metadatos y se deberán proporcionar instrucciones para acceder a los datos en el campo de descripción.
Other¶
Cualquier otro producto de datos que no se ajuste a las categorías anteriores puede cargarse como producto de tipo Other. Este es un tipo de producto genérico que permite a los usuarios cargar cualquier formato de archivo y proporcionar una descripción del producto de datos en el campo de descripción.
API y biblioteca Python¶
El Photo-z Server también ofrece una API y una biblioteca Python para facilitar el acceso a datos y metadatos mediante línea de comandos. La API contiene funciones para explorar los productos de datos disponibles, recuperar el contenido de un producto de datos determinado para trabajar en memoria o descargar los archivos de interés.
El paquete Python pzserver es de código abierto y está disponible en GitHub. Puede instalarse mediante pip con:
pip install pzserver
Tutorial notebook¶
Un notebook de tutorial con ejemplos de todos los métodos de pzserver está disponible en el repositorio de la biblioteca pzserver en GitHub. También está disponible la página de documentación de la API con más detalles orientados a desarrolladores.
Token de acceso¶
Una vez instalada e importada en un entorno Python, la clase PzServer abre la conexión remota con la base de datos del Photo-z Server.
from pzserver import PzServer
pz_server = PzServer(token="<pegue aquí su token de acceso>")
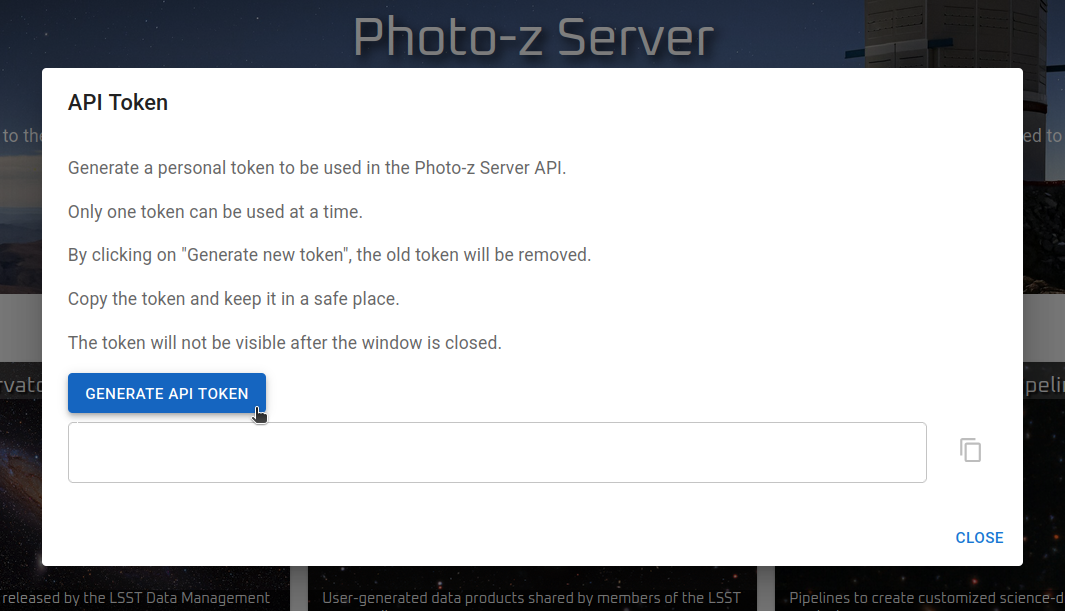
Se requiere un token de acceso para la autenticación. Los usuarios pueden generarlo en el sitio web del Photo-z Server (menú en la esquina superior derecha de la página de inicio).
Comandos básicos¶
Comandos básicos para mostrar datos y metadatos en una celda de Jupyter Notebook (si no se encuentra en un Jupyter Notebook, sustituya display por get para devolver los resultados como diccionarios Python):
pz_server.display_product_types()
pz_server.display_releases()
pz_server.display_products_list()
pz_server.display_products_list(filters={"release": "DP1",
"product_type": "Training Set"})
search_results = pz_server.get_products_list(filters={"product_type": "results"})
pz_server.display_product_metadata(id or "internal_name")
Comandos básicos para descargar o devolver datos en memoria:
pz_server.download_product(id or "internal_name", save_in=".")
data = pz_server.get_product(id or "internal_name")
Consulte el notebook de tutorial para obtener la lista completa de ejemplos, incluyendo instrucciones para carga y edición de metadatos mediante la biblioteca pzserver.
Pipelines de Photo-z Server¶
Los pipelines del Photo-z Server son un conjunto de herramientas para ayudar a los usuarios a crear y gestionar productos de datos. Los pipelines actualmente disponibles son (haga clic en los enlaces para más detalles):
Combine Redshift Catalog¶
Training Set Maker¶
Código abierto¶
El Photo-z Server es un proyecto de código abierto. Su código fuente está disponible en los siguientes repositorios de GitHub:
- pzserver_app: el código principal de la aplicación, incluyendo la interfaz web y la API.
- pzserver: la biblioteca Python utilizada para acceder a la API del Photo-z Server.
- pzserver_pipelines: el código de los pipelines disponibles en Photo-z Server.
- orchestration: la aplicación encargada de enviar los pipelines al clúster HPC de IDAC y gestionar su ejecución.
- pz-lsst-inkind: código para tareas de gestión de datos en el programa in-kind del Photo-z Server, incluyendo preparación de datos, control de calidad y notebooks de validación de pipelines.
- pz-lsst-inkind-doc: documentación de alto nivel sobre el programa in-kind del Photo-z Server, publicada a través de GitHub Pages.
El código está licenciado bajo la Licencia MIT. ¡Las contribuciones son bienvenidas!
Agradecimientos¶
Photo-z Server utiliza recursos computacionales de IDAC-Brasil en el Laboratório Interinstitucional de e-Astronomia (LIneA) con apoyo financiero del INCT do e-Universo (Proceso n.º 465376/2014-2) y del proyecto FINEP: LIneA: Centro de e-Ciencia para la exploración de los misterios del Universo y apoyo a proyectos de Big Data (ref. n.º 0883/24).