Storage
LustreFS (HPC)¶
The Apollo cluster environment features a high-performance Lustre filesystem with two storage tiers: SSD with ~70TB (T0) and HDD with ~500TB (T1), both connected to a 100Gb/s EDR Infiniband network. Both storage tiers are available at /scratch and /data.
/scratch area and quota¶
Users will be able to access their Scratch directory through the environment variable, or accessing the directory with the full path.
cd $SCRATCH
cd /scratch/users/<username>
ATTENTION
There is no backup of /scratch!
Files that have not been modified in the last 30 days will be automatically removed, which makes file storage temporary in this area.
It is recommended that users will transfer the important $SCRATCH files to their homedir.
Warning
The cleaning script runs once a week, always on weekends.
The standard quota of /scratch available to users entitled to use the cluster is:
| area | bsoft | bhard | isoft | ihard | grace period |
|---|---|---|---|---|---|
| /scratch | 35 GB | 40 GB | 100000 | 120000 | 7 days |
Best Practices¶
Distributed filesystems like Lustre are ideal for HPC and HTC environments. These environments typically handle large files that need to be accessed from many compute nodes with very high bandwidth and/or low latency. Therefore, these filesystems are quite different from those used in desktop computers or standalone servers. While excellent at handling large files, they have strong limitations when dealing with small files and access patterns more commonly found in corporate and desktop environments. Operations that might be extremely fast on a local workstation disk can be painfully slow and expensive on a Lustre filesystem, affecting both the users performing these operations and potentially all other users. These best practices and recommendations aim to enable smooth use of Lustre by minimizing or avoiding unnecessary or very expensive filesystem operations.
Avoid accessing file and directory attributes
Accessing metadata information like file attributes (e.g., type, ownership, protection, size, dates, etc.) on Lustre consumes significant resources and can degrade filesystem performance, especially when performed frequently or on directories containing many files. Minimize use of system calls that access or modify these attributes, such as stat(), statx(), open(), openat(), etc.
The same applies to commands like ls -l or ls --color that use the aforementioned calls. Instead, use a simple ls or ls -l filename.
Avoid commands that massively access metadata
Avoid using commands like ls -R, find, locate, du, df and similar. These commands recursively traverse the filesystem and/or perform heavy metadata operations. They are very intensive in filesystem metadata access and can severely degrade overall filesystem performance. If you absolutely need to recursively traverse the filesystem, use the Lustre-provided command lfs find instead of find, for example.
Use the Lustre lfs command
To minimize the number of Lustre RPC calls, whenever possible use lfs commands instead of system-provided ones:
lfs df=> instead ofdflfs find=> instead offind
Avoid using wildcards
Wildcard expansion is resource-intensive. Running commands with wildcards on a large number of files can take a long time and severely impact filesystem performance. Instead of using wildcards, create a list of target files and apply the command to each file.
Read-only access
Whenever possible, open files as read-only using O_RDONLY, and if you don't need to update file access time, open files as O_RDONLY | O_NOATIME. If access time information is needed during parallel I/O, have the parent process open files as O_RDONLY and all other ranks open the same files as O_RDONLY|O_NOATIME.
Avoid having many files in a single directory
When a file is accessed, Lustre locks its parent directory. When many files in the same directory need to be opened, this creates contention. Writing thousands of files to a single directory produces massive load on Lustre metadata servers, often resulting in filesystem unavailability. Accessing a single directory containing thousands of files can cause significant resource contention, degrading filesystem performance.
The alternative is to organize data into multiple subdirectories and distribute files among them. A common approach is to use the square root of the number of files - for 90,000 files the square root would be 300, so create 300 directories containing 300 files each.
Avoid small files
Accessing small files on Lustre is very inefficient. The recommended file size is above 1GB. Reorganize data into large files or use file formats like HDF5. Alternatively, if the total file size is small (a few GB), copy small files to /tmp or to a local temporary directory on each compute node at job start (remember to transfer and/or delete files at the end). This approach can be combined with archiving tools like tar - storing small files in one or more large tarballs can be maintained on Lustre more efficiently.
When reading or writing files, Lustre performs much better with large buffer sizes (>= 1MB). It's highly recommended to aggregate small read/write operations into larger ones. MPI-IO collective buffering allows aggregated I/O.
Avoid repetitive small file operations
Avoid performing repetitive small I/O operations like frequently opening files in append mode, writing small amounts of data, and closing the file. Instead, open the file once, perform all I/O operations, then close.
Avoid multiple processes opening the same files simultaneously
Multiple processes opening the same files simultaneously can create contention and file opening errors. Instead, perform the opening from a single (parent) process, or open the file read-only to avoid locking, or implement opening with a try-and-error approach with sleep on error.
Avoid multiple processes accessing the same file region
If multiple processes access the same file region simultaneously, the Lustre distributed lock manager will enforce coherence so all clients see consistent results. Having many processes trying to access the same file region simultaneously can cause performance degradation.
In this case, it may be preferable to: replicate the file, split the file, perform I/O operations from a single process rank, or ensure simultaneous access won't occur. In any case, it's recommended to keep the amount of parallel file opening and locking operations as small as possible to reduce contention.
If multiple processes try to append to the same file, this will trigger locking and may cause significant contention. Ideally, only one process should append to each file.
File operations through parent process
When accessing small shared files in a parallel task, it's often more efficient to perform all required operations through the parent process and, if needed, broadcast the data to other ranks, rather than accessing the same files from all ranks. Similarly, if multiple ranks of a parallel job require information about a particular file, the most efficient approach is to have the parent process perform the necessary calls (e.g. stat(), fstat(), etc) and then broadcast the information to other ranks.
File striping
In Lustre, large files can be split into segments that can be automatically distributed across multiple storage devices. File striping is useful for parallel I/O on large files. For this to work, the mount point in question must point to multiple storage devices (OSTs). The lfs df command can be used to verify if a given mount point points to multiple OSTs. To get striping information for a particular file, use:
lfs getstripe filename
File striping can be set using the lfs setstripe command. If applied to a directory, it will set default striping settings for files created in that directory. A subdirectory inherits all striping settings from its parent directory. If applied to a file, it will stripe that file across OSTs according to the specified settings.
lfs setstripe -s 128m -c 8 filename => splits the file into 128MB segments and distributes them across 8 OSTs
If a large file is shared in parallel by multiple processes, with each process working on its own part of the file, then it may be useful to stripe the file into a number of segments equal to the number of processes, or a multiple of the number of processes.
For maximum performance, I/O requests should be aligned to stripes, meaning processes accessing the file should do so at offsets matching stripe boundaries. This minimizes the chances of a process needing to access more than one stripe (and more than one OST) to get required data.
For small files, striping should be disabled by setting a stripe count of 1. The same applies if a large file is accessed by a single process.
lfs setstripe -s 1m -c 1 mydir/smallfiles/
Avoid installing software on Lustre
Software typically consists of many small files, and as mentioned earlier, accessing many small files on Lustre can overload metadata servers. Software compilations in particular are better performed locally by copying or unpacking the software to /tmp/$USER/ or to your homedir.
Additionally, under high load, I/O access to Lustre filesystems may be blocked. If executables are stored on Lustre and filesystem access fails, executables may crash. Therefore, whenever possible, it's better to copy executables to cluster nodes' /tmp.
/scripts area¶
Users will be able to access their script directory through the environment variable, or accessing the directory with the full path.
cd $SCRIPTS
cd /scripts/<username>
This area is intended for the storage of Jobs submission scripts to the cluster and others. It is also recommended to use this path to the creation of Python environments (envs) and kernels.
The standard quota of /scripts available to users is:
| area | bsoft | bhard | isoft | ihard | grace period |
|---|---|---|---|---|---|
| /scripts | 10 GB | 12 GB | 100k | 120k | 7 days |
Note: The /scripts is not affected by the automatic cleaning process.
Homedir¶
The Home directory is an area for users to store their personal files and is accessible through the cluster login nodes and also on the Jupyter platform.
The standard quota of homedir available to users, according to their profile, is:
| profile | bsoft | bhard | isoft | ihard | grace period |
|---|---|---|---|---|---|
| public general | 5 GB | 7 GB | 7000 | 10000 | 7 days |
| public institutional | 25 GB | 30 GB | 40000 | 50000 | 7 days |
| LSST collaboration | 35 GB | 40 GB | 1000000 | 1200000 | 7 days |
Tip
To check the quota values configured simply use the command: quota -s -u <username> /home.
Note: The /home directory is not affected by the automatic cleaning process.
Useful Commands¶
a) How to check my available quota?
show_quota
b) How to check a project's available quota?
show_proj_quota <projeto>
c) How to find my files created more than 30 days ago?
lfs find $SCRATCH --uid $UID -mtime +30 --print
d) How to find my files created less than 30 days ago?
lfs find $SCRATCH --uid $UID -mtime -30 --print
e) How to list Lustre OSTs?
lfs osts $SCRATCH
f) How to list files older than 30 days on a specific Lustre OST?
lfs find $SCRATCH -mtime +30 --print --obd t0-OST0002_UUID
g) How to configure striping on a directory to "split" files and distribute "chunks" across 10 OSTs?
lfs setstripe -c 10 $SCRATCH/my_large_files
h) How to check file/directory striping?
lfs getstripe $SCRATCH/my_large_files
Tip
LIneA's Lustre is designed to work at 100Gbps - to achieve maximum performance use striping and always with large files (+1GB).
NAS (NFS)¶
NAS storage systems are used for long-term storage and are not accessible through compute nodes (HPC).
Current specifications:
| Manufacturer | Model | Capacity | Installed | Availability |
|---|---|---|---|---|
| SGI | IS5600 | 240TB | Jul-2014 | Available |
| HPE | APOLO 4510 | 1.2 PB | Apr-2025 | Available |
Backup¶
| areas | incremental backup (daily) | full backup (mothly) | retention |
|---|---|---|---|
| /home |  |
|
90 days |
| /data |  |
|
- |
| /scratch | |
|
- |
| /scripts | |
|
- |
Info
Although it does not have a backup schedule, the /data volume is composed of a robust disk redundancy system that preserves the integrity of your data.
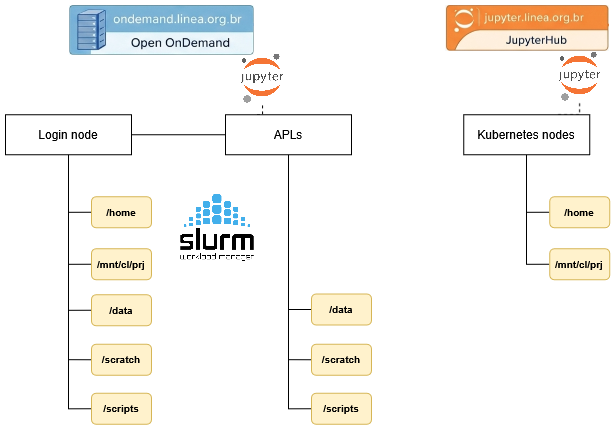
Overview of storage areas¶
References¶
These best practices were compiled from LIneA team experience and the following sources:
- https://www.nas.nasa.gov/hecc/support/kb/lustre-best-practices_226.html
- https://hpcf.umbc.edu/general-productivity/lustre-best-practices/
- https://wiki.gsi.de/foswiki/bin/view/Linux/LustreFs
- https://doc.lustre.org/lustre_manual.pdf