JupyterHub
O JupyterHub é um ambiente de desenvolvimento multiusuário baseado em iPython Notebooks que oferece acesso a recursos computacionais compartilhados em um servidor remoto, sem a necessidade de instalação e manutenção por parte dos usuários. Os únicos pré-requisitos para acessar o JupyterHub são: ter uma conta de usuário no LIneA (veja aqui como criar sua conta) e um navegador com acesso à Internet. Os chamados Jupyter Notebooks permitem combinar código interativo, resultados de execução, texto explicativo e recursos de multimídia em um só documento.
Como parte do LIneA Science Platform, o LIneA JupyterHub está integrado às demais ferramentas de visualização e acesso a dados. Desse modo, toda a análise de dados pode ser feita online dentro da plataforma, desde a leitura, visualização, processamento e análise de resultados, sem a necessidade de download dos dados para o computador pessoal do usuário.
Tela inicial¶
Ao clicar no card "JupyterHub" dentro do LIneA Science Platform (ou acessando diretamente no endereço jupyter.linea.org.br), você será direcionado para a página de login e em seguida para a página inicial que mostra as diferentes opções de configuração para o servidor Jupyter.
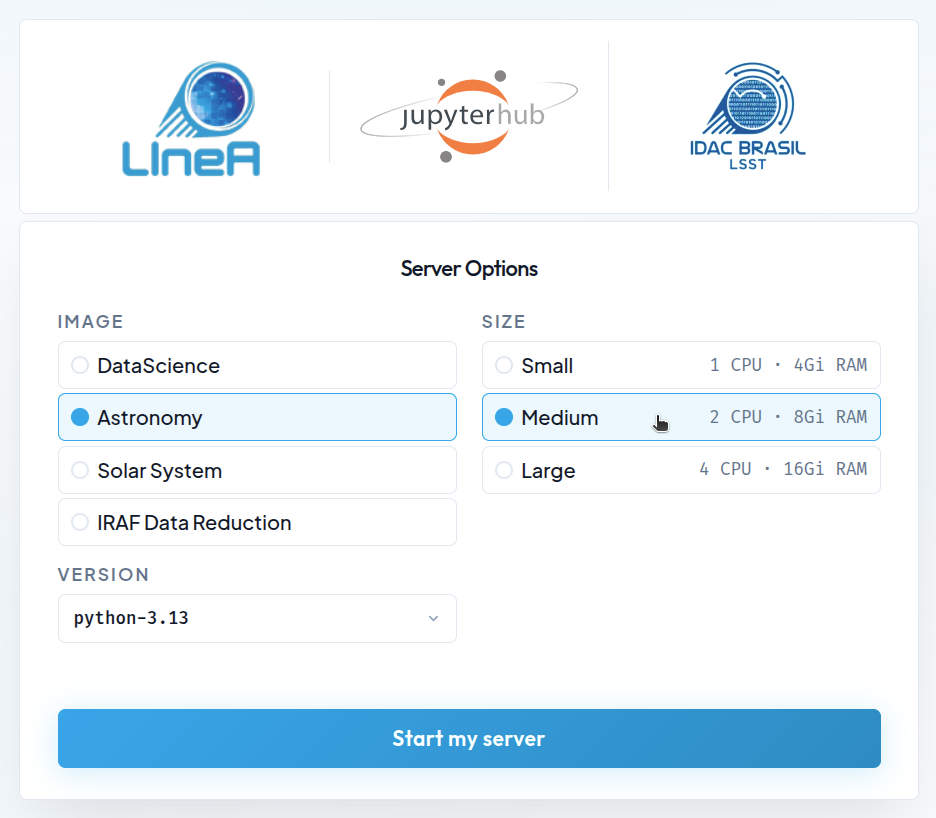
Configurações disponíveis¶
Imagens Docker pré-configuradas¶
A instalação padrão do LIneA JupyterHub é baseada em Docker containers com ambientes previamente configurados para atender a maioria das demandas dos usuários. São quatro opções de imagens Docker disponíveis:
- DataScience – o stack Jupyter Data Science Notebook, incluindo bibliotecas populares de data science como Pandas, NumPy, Matplotlib, SciPy e Scikit-learn.
- Astronomy – o stack genérico de astronomia, que inclui as principais bibliotecas de data science mais as bibliotecas mais utilizadas na área, como Astropy, Astroquery, Healpy, Photutils, PyVO, Dustmaps, LSDB, AstroML, entre outras.
- SolarSystem – o stack específico para a área de estudos do Sistema Solar, que inclui as principais bibliotecas das imagens DataScience e Astronomy mais as bibliotecas mais utilizadas na área, como sbpy, spiceypy, rebound, sora-astro, reboundx, entre outras.
- IRAF Data Reduction – uma imagem customizada para auxiliar tarefas que dependem de redução e manipulação de imagens astronômicas com ferramentas tradicionais como IRAF e DS9 (ferramentas mais modernas como o Astropy CCDProc, Photutils e Reproject estão disponíveis na imagem Astronomy).
Confira aqui a lista com as principais bibliotecas incluídas nos ambientes e links para as suas respectivas documentações.
| Categoria | Biblioteca | Para que serve | Doc |
|---|---|---|---|
| Ciência de Dados e ML |
corner | Visualização de distribuições posteriores. | doc |
| dynesty | Nested sampling bayesiano. | doc | |
| emcee | Amostragem MCMC. | doc | |
| lmfit | Ajuste de modelos não lineares. | doc | |
| NumPy | Operações numéricas e arrays multidimensionais. | doc | |
| Pandas | Análise de tabelas e manipulação de dados. | doc | |
| scikit-image | Processamento de imagens. | doc | |
| scikit-learn | Machine learning e modelos preditivos. | doc | |
| SciPy | Funções científicas avançadas e métodos numéricos. | doc | |
| Visualização | Bokeh | Visualizações interativas para web. | doc |
| Datashader | Renderização de grandes volumes de dados. | doc | |
| HoloViews | Visualização declarativa de dados. | doc | |
| hvPlot | API de alto nível para visualização. | doc | |
| Matplotlib | Visualização científica 2D/3D. | doc | |
| Plotly | Gráficos interativos e dashboards. | doc | |
| Seaborn | Visualizações estatísticas de alto nível. | doc | |
| Banco de Dados, Jupyter e Utilitários |
psycopg2 | Conector PostgreSQL para Python. | doc |
| SQLAlchemy | ORM e toolkit SQL para manipulação de bancos de dados. | doc | |
| pooch | Gerenciamento de download de datasets. | doc | |
| Dask | Paralelização e computação distribuída. | doc | |
| IPykernel | Kernel Python para notebooks. | doc | |
| Astronomia | astrocut | Recorte de imagens astronômicas. | doc |
| astroML | Machine learning aplicado à astronomia. | doc | |
| Astropy | Núcleo de ferramentas astronômicas. | doc | |
| Astroquery | Consultas a arquivos e catálogos astronômicos online. | doc | |
| Cartopy | Mapas e projeções geoespaciais. | doc | |
| Dustmaps | Mapas de extinção da Via Láctea. | doc | |
| HATS Import | Conversão de catálogos para formato HATS. | doc | |
| Healpy | Manipulação de mapas HEALPix. | doc | |
| ipyaladin | Visualização interativa do céu (Aladin Lite no Jupyter). | doc | |
| lineassp | API do LIneA Solar System Portal. | doc | |
| lightkurve | Análise de curvas de luz (Kepler/TESS). | doc | |
| LSDB | Análise escalável de catálogos. | doc | |
| Photutils | Fotometria e detecção de fontes. | doc | |
| pyspeckit | Ajuste e análise de espectros. | doc | |
| pyspac | Análise e Caracterização da Curva de Fase Solar | doc | |
| PyVO | Acesso a serviços do Virtual Observatory. | doc | |
| pzserver | Acesso a dados e execução de pipelines do PZ Server de forma remota. | doc | |
| rail | Pipeline de redshift fotométrico. | doc | |
| Regions | Manipulação de regiões no céu. | doc | |
| Reproject | Reprojeção de imagens astronômicas. | doc | |
| specutils | Análise espectral astronômica. | doc | |
| Sistema Solar |
rebound | Simulações N-corpos. | doc |
| reboundx | Extensões para REBOUND. | doc | |
| sbpy | Ferramentas para ciência de pequenos corpos. | doc | |
| spiceypy | Interface Python para SPICE (NASA). | doc | |
| sora-astro | Análise de ocultações estelares. | doc |
Recursos computacionais¶
Configuração dos servidores do ambiente K8S
A plataforma JupyterHub é executada sobre um cluster Kubernetes (K8S) e possui 12 servidores físicos dedicados. Cada máquina é equipada com os seguintes recursos computacionais:
| Kubernetes Node Configuration | |
|---|---|
| RAM | 64 GB |
| Threads per core | 2 |
| Cores per socket | 6 |
| Sockets | 2 |
Configurações disponíveis para os usuários
Ainda na página inicial, do lado direito será exibido um menu com até três opções de recursos computacionais que serão reservados para o servidor Jupyter de cada usuário simultaneamente. As opções disponíveis são as seguintes:
| Tamanho | CPUs | RAM |
|---|---|---|
| Small | 1.0 | 4 GiB |
| Medium | 2.0 | 8 GiB |
| Large | 4.0 | 16 GiB |
As opções que oferecem mais de uma CPU permitem a execução de código paralelo, o que pode ser útil para tarefas que se beneficiam de múltiplos núcleos, como simulações numéricas, ou treinamento de modelos de machine learning. No entanto, o JupyterHub baseado em K8S é projetado para ser um ambiente de desenvolvimento leve e interativo, e não é otimizado para cargas de trabalho intensivas em CPU ou memória. Para tarefas mais exigentes, que envolvem processamento de dados em larga escala ou treinamento de modelos complexos, recomenda-se a utilização do outro serviço de Jupyter disponível na plataforma Ondemand, que tem acesso direto à infraestrutura de HPC do LIneA.
Jupyter over K8S vs Jupyter over HPC
O LIneA disponibiliza dois ambientes separados de Jupyter Notebook. O primeiro é executado em containers na plataforma Kubernetes (K8S) e está integrado ao banco de dados Postgres e ao sistema de arquivos. O segundo está disponível na plataforma Ondemand e acessa diretamente a infraestrutura de HPC.
Gerenciamento de ambientes¶
Caso seu trabalho necessite de outras bibliotecas ou da fixação de versões específicas de alguma delas, recomendamos a utilização do gerenciador de pacotes Conda. Para saber mais, acesse o tutorial oficial do Conda e a Cheat Sheet disponibilizada pelo projeto com a lista de comandos mais úteis.
Como criar um ambiente customizado¶
Por exemplo, vamos criar um ambiente com Python 3.12 chamado myenv. Para abrir um Terminal, no menu superior do Jupyter Lab, clique em:
File > New > Terminal
Vamos começar verificando os ambientes disponíveis.
conda env list
Se está acessando pela primeira vez, deve ver apenas o ambiente base disponível.
Criando o novo ambiente:
conda create -n myenv python=3.12
Ativar o ambiente
Para ativar o ambiente:
conda activate myenv
Depois disso, você pode instalar pacotes normalmente com o próprio Conda, ou com Pip. Por exemplo:
conda install numpy=1.26
pip install astropy=7.1
Para que o novo ambiente esteja disponível para ser utilizado em um notebook, precisamos registrá-lo como um kernel.
Como registrar o ambiente como kernel do Jupyter¶
Criar novo kernel
A criação de um novo kernel a partir de um ambiente conda é feita pela biblioteca ipykernel. Ela já está disponível no ambiente base.
python -m ipykernel install --user --name myenv --display-name "MyEnv"
Depois de criados, os kernels ficam disponíveis para a inicialização de novos notebooks na aba "Launcher", ou podem ser selecionados no menu do canto superior direito do notebook. Para listar os kernels existentes:
Remover o kernel
Para remover um kernel:
jupyter kernelspec remove myenv
Remover ambiente
Se desejar remover o ambiente:
conda env remove --name myenv
Acesso a dados¶
Banco de dados¶
O LIneA possui um banco de dados dedicado ao armazenamento de dados astronômicos tabulares gerenciado pelo sistema Postgres. Este banco armazena catálogos, mapas e tabelas auxiliares liberados por levantamentos astronômicos e tabelas criadas pelos usuários como resultados de consultas ou uploads. O acesso aos dados hospedados no banco a partir de um notebook no JupyterHub é feito com a biblioteca pyvo através do serviço TAP, com consultas programáticas nas linguagens SQL ou ADQL.
Setup
Para conectar na API do serviço TAP do LIneA, utilizaremos as bibliotecas requests e PyVO, um pacote afiliado ao Astropy que permite consultas remotas de dados astronômicos de repositórios que seguem o padrão de protocolos de serviço IVOA.
import pyvo
import requests
O primeiro passo é abrir uma conexão com o serviço TAP do LIneA:
tap_session = requests.Session()
tap_url = "https://userquery.linea.org.br/tap"
tap_service = pyvo.dal.TAPService(tap_url, session=tap_session)
Em seguida, podemos realizar consultas utilizando a linguagem SQL ou ADQL. Por exemplo, para consultar a tabela gaia_dr3.gaia_source e obter as 10 primeiras linhas:
query = "SELECT TOP 10 * FROM gaia_dr3.gaia_source"
result = tap_service.search(query)
O resultado da consulta é retornado como um objeto do tipo pyvo.dal.TAPResults, que pode ser convertido para um astropy.table.Table, que por sua vez, pode ser convertito em Pandas DataFrame (opcional) para facilitar a manipulação e análise dos dados:
from astropy.table import Table
import pandas as pd
table = Table(result.to_table())
df = table.to_pandas()
Acesse aqui a documentação completa sobre o acesso ao banco de dados Postgres do LIneA com a biblioteca pyvo: TAP Service
LSDB¶
O Large Scale Database (LSDB) é uma biblioteca Python desenvolvida pelo LSST Interdisciplinary Network for Collaboration and Computing (LINCC) no âmbito do Legacy Survey of Space and Time (LSST), projetada para facilitar o acesso e a análise de grandes conjuntos de dados astronômicos. Um amplo acervo de dados públicos é disponibilizado pelo projeto no site LSDB.io.
O LIneA hospeda uma cópia local desses dados, integrando-se ao ecossistema internacional do LSDB.io. Essa infraestrutura oferece maior eficiência na transferência de dados para usuários geograficamente próximos ao Brasil e permite que a comunidade astronômica brasileira acesse e analise esses conjuntos de dados de forma otimizada, utilizando seus recursos de computação de alto desempenho (HPC).
O acesso aos dados do LSDB a partir do JupyterHub é feito com a biblioteca lsdb, que oferece uma interface Python para realizar consultas e manipular os dados armazenados no LSDB. Apesar de o LSDB ser otimizado para manipulação de grandes volumes, ele também pode ser útil para pequenas consultas. Visite a lista de tutoriais da página oficial do LSDB para saber mais sobre como aproveitar esta grande ferramenta em todo o seu potencial.
Para fazer uma consulta simples, basta importar a biblioteca e abrir um catálogo específico. Por exemplo, para acessar o catálogo de objetos do DES DR2 hospedado no LSDB do LIneA:
import lsdb
import pandas as pd
O LSDB utiliza a metodologia de computação "preguiçosa", onde os comandos são planejados a priori e as operações são realizadas somente no final do processo.
O comando abaixo ainda não traz os dados para a memória local, apenas planeja que vai trazer estas colunas do catálogo localizado pela URL informada.
cat = lsdb.open_catalog("https://linea.data.lsdb.io/hats/des/des_dr2",
columns=["COADD_OBJECT_ID", "RA", "DEC", "MAG_AUTO_G_DERED", "MAG_AUTO_R_DERED",
"EXTENDED_CLASS_COADD", "FLAGS_G", "FLAGS_R"])
A variável cat guarda um objeto do tipo Catalog que tem métodos e atributos a serem utilizados, também de forma preguiçosa, sem efetuar os cálculos. Por exemplo, vamos fazer uma busca espacial na região do aglomerado de estrelas de Sculptor, com um raio de 0.5 graus:
sculptor_stars = cat.cone_search(ra=15.03875, dec=-33.70916667, radius_arcsec=0.5 * 3600)
Após definir as colunas e a região de interesse, podemos executar a consulta com o método compute() e finalmente trazer os dados para um Pandas DataFrame:
df = sculptor_stars.compute()
Tutoriais em Jupyter Notebooks¶
No menu Tutorials na barra superior do Jupyter lab você encontra modelos de notebooks contendo exemplos de uso para aprender como:
- Utilizar um Jupyter Notebook (caso seja iniciante)
- Customizar o seu ambiente com bibliotecas e versões específicas
- Acessar os dados hospedados no LIneA diretamente a partir de um notebook

Os tutorias estão disponíveis no repositório público do LIneA no GitHub jupyterhub-tutorial, e são atualizados regularmente para incluir novos exemplos de uso e cobrir as dúvidas mais frequentes dos usuários. Ao clicar em um tutorial específico, o sistema faz uma cópia do notebook para o diretório atual na área do usuário, garantindo que cada pessoa possa executar e fazer alterações na(s) sua(s) cópia(s).
Ao logar no JupyterHub, o sistema cria uma cópia de todos os notebooks de tutoriais para um diretório $HOME/notebooks/tutorials/ na área do usuário. Não recomenda-se a alteração dos arquivos originais, para evitar que as atualizações futuras sejam perdidas. Caso queira manter uma cópia personalizada, recomendamos usar sempre o menu Tutorials para criar uma nova cópia atualizada no diretório atual de trabalho.
Assistente de IA (experimental)¶
O assistente de IA no JupyterLab é fornecido pela extensão Jupyter AI (v2) e suporta os magic commands %ai e %%ai.
Uso rápido (fluxo mínimo)¶
%load_ext jupyter_ai_magics
%ai list
%%ai coder1b
Descreva o teorema de Pitágoras
Opcional (para contexto maior, no chat):
/learn *.ipynb
/ask Resuma este notebook.
1) Chat Jupyternaut¶
No JupyterLab, abra o painel lateral do Jupyternaut (ícone de chat). Depois de configurar modelo/chaves, você pode usar comandos de barra (/) no próprio chat:
/learn <caminho|padrão>: indexa arquivos locais para uso como contexto./ask <pergunta>: pergunta especificamente sobre o conteúdo aprendido com/learn./learn -d: limpa a base local de conhecimento criada pelo/learn./fix: ajuda a corrigir célula com erro (o chat pede a seleção da célula com erro)./export [arquivo.md]: exporta o histórico da conversa para Markdown./clear: inicia uma nova conversa e limpa o contexto do chat atual.
Uso prático do /learn (diferencial)¶
No LIneA, o /learn usa embeddings locais (modelo padrão nomic-embed-text).
O conteúdo é processado em partes (chunks) e convertido em embeddings locais.
Esses dados são usados para recuperação de contexto (RAG) durante o chat.
Características:
- não altera o modelo;
- não é memória permanente (pode ser limpo com
/learn -d); - ideal para documentação, notebooks e código;
- onde fica armazenado: base vetorial local do Jupyter AI em
~/.local/share/jupyter/jupyter_ai; - chunking no LIneA é controlado por
LINEA_CHUNK_SIZE(default 1200) eLINEA_CHUNK_OVERLAP(default 240). Por isso, os parâmetros-c/-opodem ser sobrescritos pelo ambiente/policy; - por padrão ignora
node_modules,lib,builde arquivos ocultos (use-apara incluir tudo).
Quando usar cada comando:
**/ask**: quando a pergunta depende dos arquivos indexados por/learn(pergunta contextual sobre documentação/código local).- Chat normal: quando a pergunta é geral e não depende do conteúdo local indexado.
Exemplo real:
/learn docs/
/ask Quais são os endpoints da API?
Chat vs Magics: quando usar cada um¶
| Ferramenta | Uso recomendado |
|---|---|
| Chat (Jupyternaut) | exploração, perguntas gerais, uso com /learn |
%%ai |
execução estruturada dentro do notebook |
%ai |
comandos auxiliares (listar modelos, reset, aliases etc.) |
2) Magic commands¶
Antes de usar os comandos:
%load_ext jupyter_ai_magics
Comandos principais:
%%ai <provedor:modelo>(ou alias): envia prompt em célula para um modelo.
Exemplo:%%ai coder1b Resuma os pontos principais desta análise.%ai helpe%%ai help: ajuda de sintaxe e opções.%ai list [provedor]: lista modelos disponíveis (geral ou por provedor).%ai reset: limpa o histórico usado como contexto nas próximas chamadas.%ai error <provedor:modelo>: explica o erro mais recente do notebook.%ai register <alias> <provedor:modelo>: cria alias de modelo.%ai update <alias> <novo-provedor:modelo>: atualiza alias.%ai delete <alias>: remove alias.
Recursos úteis do %%ai:
- formato de saída com
-f/--format(code,markdown,math,html,json,text,image); - interpolação de variáveis com
{variavel}no prompt; - definição de modelo padrão:
%config AiMagics.default_language_model = "linea:qwen2.5-coder:1.5b"
Escopo dos %%ai:
Os comandos %%ai não têm acesso automático ao conteúdo de outras células do notebook.
Por padrão, o modelo recebe apenas:
- o texto da célula atual;
- variáveis explicitamente interpoladas no prompt (ex.:
{variavel}).
Exemplo que não funciona como esperado:
%%ai coder1b
Explique como este notebook está organizado.
Nesse caso, o modelo não recebe o restante do notebook e a resposta tende a ser genérica.
Como fornecer contexto corretamente¶
- Interpolar variáveis Python:
conteudo = "texto de outra célula ou análise"
%%ai coder1b
Explique:
{conteudo}
- Usar
/learnpara múltiplos arquivos ou notebooks (no chat):
/learn *.ipynb
/ask Como este notebook está organizado?
Nesse modo, o assistente usa embeddings para recuperar trechos relevantes automaticamente.
3) Modelos externos (configuração)¶
Há dois cenários de uso:
- Local (LIneA): funciona out of the box, sem chave de API. Os modelos são, no entanto menores e mais suscetíveis a alucinações
- Externo (provedores de terceiros): exige configuração de credenciais e, em alguns casos, dependências adicionais.
Fluxo para provider externo:
- configure credenciais (variáveis de ambiente ou painel de configurações do chat);
- confirme com
%ai listse o modelo está disponível.
Chaves persistentes (~/.linea/apikeys.env)¶
O ambiente do LIneA pode manter suas credenciais em um arquivo no seu HOME:
~/.linea/apikeys.env
Esse arquivo contém variáveis como OPENAI_API_KEY, GROQ_API_KEY, NVIDIA_API_KEY, ANTHROPIC_API_KEY e GOOGLE_API_KEY.
Para mudanças terem efeito, reinicie o kernel/sessão (ou reinicie o JupyterLab) após editar esse arquivo.
Provider local LIneA¶
Além dos provedores externos, o ambiente também expõe:
- Provider
linea(chat local via Ollama, sem chave de API); - Provider
linea(embeddings, exibido no seletor como LIneA (embeddings));
Modelos de chat locais disponíveis no provider linea:
qwen2.5-coder:0.5bqwen2.5-coder:1.5bqwen2.5-coder:3bqwen2.5-coder:7b
Atenção
Os modelos Qwen2.5-Coder são otimizados para tarefas de programação, com tamanhos variando de 0.5B a 7B parâmetros para diferentes trade-offs entre velocidade e qualidade. Use os modelos menores (0.5B-1.5B) para tarefas simples e respostas rápidas em ambientes com recursos limitados, e os maiores (3B-7B) para problemas mais complexos; tenha cuidado ao usar modelos pequenos para lógica intrincada ou requisitos de segurança críticos, pois tendem a alucinar e cometer erros, e lembre-se que eles não têm acesso automático ao contexto completo do notebook, então interpole variáveis ou conteúdo relevante explicitamente no prompt para melhores resultados.
Exemplos:
%load_ext jupyter_ai_magics
%ai list linea
%%ai coder1b
Escreva uma função Python para ler um CSV usando numpy.
Por padrão, o ambiente já inclui aliases para o provider linea.
Para usar somente o modelo de 1.5b, use coder1b (equivale a linea:qwen2.5-coder:1.5b):
%%ai linea:qwen2.5-coder:1.5b
Escreva uma função Python para ler um CSV usando numpy.
Para modelos mais potentes e acesso gratuito busque por provedores que oferecam algum nível de acesso gratuito. Providers como a startup groq (https://console.groq.com/home) ou nividia (https://build.nvidia.com/) oferecem camadas de acesso gratuitas via chaves API.
Provider groq:
- autenticação: informar a chave no campo
GROQ_API_KEYnas configurações do Jupyter AI.
Exemplo de uso com provider externo (Groq):
%env GROQ_API_KEY=SUA_CHAVE_GROQ
%ai list groq
%%ai groq:<SEU_MODEL_ID>
Resuma os pontos principais deste notebook.
Provider nvidia:
- autenticação: informar a chave no campo
NVIDIA_API_KEYnas configurações do Jupyter AI.
Exemplo de uso com provider externo (NVIDIA):
%env NVIDIA_API_KEY=SUA_CHAVE_NVIDIA
%ai list nvidia
%%ai nvidia:<SEU_MODEL_ID>
Resuma os pontos principais deste notebook.
%env vs export (quando definir chaves)
Quando um provider exigir chave (ex.: groq):
%env GROQ_API_KEY=...(ouNVIDIA_API_KEY=...): aplica no kernel atual (efeito imediato para%ai/%%ai);export GROQ_API_KEY=...(ouexport NVIDIA_API_KEY=...): aplica no shell mas não necessaraiamente aplica para kernels iniciados depois. É necessario importar a variável de ambiente para dentro do código. Para persistência use chaves persistentes
Exemplo rápido com modelo local LIneA (sem chave):
%load_ext jupyter_ai_magics
%config AiMagics.default_language_model = "linea:qwen2.5-coder:1.5b"
%%ai
Explique este erro de Python e proponha uma correção.
Importante: provedores externos podem gerar custo por uso de API. Revise preços e políticas de privacidade antes de enviar dados sensíveis.
Troubleshooting básico¶
1) Modelo não aparece em %ai list
- confirme se o provider está correto (ex.:
%ai list lineaou%ai list groq); - para provider externo, verifique se dependências e credenciais foram configuradas;
- recarregue a extensão no notebook:
%load_ext jupyter_ai_magics
%ai list
2) Erro de autenticação
- para
groq, confirme seGROQ_API_KEYfoi definido no kernel atual (%env GROQ_API_KEY=...); - se a chave foi definida com
exportapós abrir o notebook, reinicie o kernel/sessão; - confira se não há espaços extras ou valor truncado na chave.
3) Kernel não reconhece %ai ou %%ai
- carregue a extensão:
%load_ext jupyter_ai_magics; - se persistir, reinicie o kernel e execute novamente;
- em kernels remotos, instale o pacote no próprio kernel com
%pip install jupyter_ai_magics.
Referência oficial: Jupyter AI v2 Documentation